
Top takeaway: MMEmb‑R1 frames chain‑of‑thought (CoT) as a latent variable and uses pair‑aware counterfactual selection plus a utility‑aware RL policy to invoke reasoning selectively. On MMEB‑V2 it sets a new SOTA (71.2 overall with a 4B backbone) while cutting reasoning latency to 185s (2.5× faster than UME‑R1) by avoiding unnecessary CoT generation.
📌 Highlights
- Core claim: treating reasoning paths r as a latent variable and selecting them via a pair‑aware counterfactual evaluator aligns instance‑level CoT with pairwise contrastive objectives and prevents shortcutting.
- Strongest result: MMEmb‑R1 (Qwen3‑VL‑4B) achieves 71.2 on MMEB‑V2, outperforming larger baselines while reducing inference latency via an adaptive RL policy.
- Primary limitation: pipeline training (offline candidate generation → selection → two‑stage training) prevents joint end‑to‑end optimization and still incurs extra inference cost for reasoning‑enabled cases.
🎯 Introduction
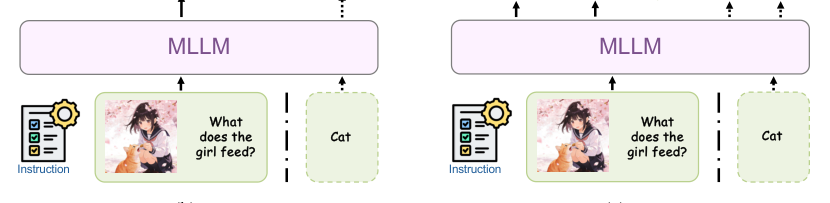
Multimodal embedding models benefit from the world knowledge and compositional reasoning of MLLMs, but prior attempts to inject CoT suffer from two problems: (1) structural misalignment — contrastive learning optimizes pairwise dependencies while CoT is produced per instance, so models can learn to ignore or superficially mimic CoT tokens; (2) reasoning is not always beneficial — forcing CoT for every input causes overthinking, higher latency, and possible performance degradation on simple cases. MMEmb‑R1 addresses both by (a) modeling reasoning as a latent variable with a simulated prior and a pair‑aware posterior selection, and (b) learning an adaptive policy (via GRPO) that invokes reasoning only when instance utility warrants it.
🔬 Methodology
Framework overview
MMEmb‑R1 has three stages: (1) diverse multi‑worker generation to simulate a prior P(R) over reasoning traces; (2) pair‑aware counterfactual selection that scores candidates r relative to a query–target pair (q,t+) and builds a weighted reasoning pool DR; (3) a two‑stage training pipeline — joint reasoning+embedding training, then utility‑aware RL to learn when to invoke reasoning.
Preliminaries and objective
Given inputs x = {t,v}, an embedding model E maps x to z = E(x) ∈ R^d. Training uses InfoNCE across N pairs {(q_k,t^+_k)}:
Reasoning as a latent variable and pair‑aware selection
Instead of a single teacher CoT, MMEmb‑R1 approximates a prior P(R) by sampling K heterogeneous workers (Instruct, Thinking, Proprietary). For each candidate rationale r and pair (q,t+), a strong evaluator J computes a baseline confidence c_0 = Conf_J(q,t+) and the with‑rationale confidence c_r = Conf_J(q,t+,r). The counterfactual gain
\Delta_r = c_r - c_0
measures marginal contribution of r to matching confidence. Candidates with \Delta_r > \epsilon are kept and normalized via softmax (temperature \gamma) into weights w_r; the resulting bundle DR = {(q_i,t^+_i,r_{i,j},w_{i,j})} is used for training.
Joint reasoning + embedding training
The model is trained with two embedding paths plus an NTP objective over CoT tokens. For a sampled reasoning r from DR we compute reasoning‑enhanced contrastive loss L_{reason} = L_{con}(z^r_q, z^r_t) and next‑token prediction loss
A direct‑embedding path is retained with L_{direct} = L_{con}(z^d_q, z^d_t). Full objective:
Adaptive reasoning control (utility‑aware RL)
After joint training we estimate per‑instance reasoning utility by comparing normalized similarities from reasoning and direct embeddings:
\delta_i = s_{r,i} - s_{d,i}, where positive \delta_i indicates benefit from reasoning.
An RL policy \pi_\theta chooses actions a_i \in {DIRECT, REASON}. The adaptive reward balances exploration, embedding gain, and reasoning cost. The paper defines:
where \mu(L_i) is a length‑based penalty (an extra cost c is applied for lengths >512 tokens). Additional terms include R_{format} (structure validity) and R_{emb} (embedding discriminativeness measured by positive/negative ranking and similarity gap). The policy is optimized with Group Relative Policy Optimization (GRPO) to avoid per‑token critics and stabilize training.

📊 Experiments
Setup
Backbones: Qwen‑VL family (Qwen2/2.5/3 VL). Diversity workers: GLM‑4.1V‑Thinking, InternVL3‑14B‑Instruct, Doubao‑Seed‑1.6‑Vision. Evaluator: Qwen3‑VL‑32B‑Instruct. Training used MMEB‑Train (filtered) yielding ≈1.2M joint samples and ≈10K RL samples. Evaluation: MMEB‑V2 (78 tasks across Image, Video, VisDoc). Metrics: Hit@1 for images/videos, NDCG@5 for VisDoc.
Main results (MMEB‑V2)
Table 1 compares MMEmb‑R1 with representative baselines aggregated by model size. MMEmb‑R1 obtains strong gains across modalities, notably on Video where reasoning yields the largest relative improvement.
| Model | Backbone | Image (Overall) | Video (Overall) | VisDoc (Overall) | All (Overall) |
|---|---|---|---|---|---|
| GME | Qwen2‑VL‑2B | 51.9 | 33.9 | 54.1 | 54.1 |
| VLM2Vec | Qwen2‑VL‑2B | 59.7 | 29.0 | 47.0 | 59.7 |
| UME‑R1 | Qwen2‑VL‑2B | 66.6 | 42.2 | 60.1 | 66.6 |
| RzenEmbed‑v1 | Qwen2‑VL‑2B | 68.5 | 42.6 | 64.4 | 68.5 |
| Embed‑RL | Qwen3‑VL‑2B | 69.2 | 52.1 | 66.8 | 69.2 |
| MMEmb‑R1 (Ours) | Qwen2‑VL‑2B | 70.0 | 50.6 | 65.0 | 65.0 |
| MMEmb‑R1 (Ours) | Qwen3‑VL‑2B | 71.5 | 55.6 | 68.3 | 68.3 |
| UME‑R1 | Qwen2‑VL‑7B | 71.3 | 47.5 | 64.5 | 71.3 |
| Embed‑RL | Qwen3‑VL‑4B | 70.1 | 53.0 | 68.1 | 70.1 |
| RzenEmbed‑v1 | Qwen2‑VL‑7B | 73.6 | 48.9 | 68.9 | 73.6 |
| MMEmb‑R1 (Ours) | Qwen2‑VL‑7B | 74.4 | 53.3 | 69.7 | 74.4 |
| MMEmb‑R1 (Ours) | Qwen3‑VL‑4B | 74.8 | 56.6 | 71.2 | 71.2 |
Key points: MMEmb‑R1 with Qwen3‑VL‑4B reaches 71.2 overall, outperforming several larger baselines; the 2B variant (Qwen3‑VL‑2B) already attains 68.3. Improvements are largest on video tasks, consistent with temporal/compositional reasoning benefits.
Latency and adaptive inference
Adaptive reasoning reduces wall‑clock inference while improving accuracy by avoiding unnecessary CoT. Measured on a subset with Qwen2‑VL‑2B backbone:
| Strategy | Latency (s) | Accuracy (MMEB‑V2 overall) |
|---|---|---|
| UME‑R1 | 459 | 60.1 |
| MMEmb‑R1 (Always reason) | 337 | 63.6 |
| MMEmb‑R1 (Adaptive) | 185 | 65.0 |
Adaptive MMEmb‑R1 attains a 2.5× speedup vs UME‑R1 and is both faster and more accurate than an always‑reason baseline.
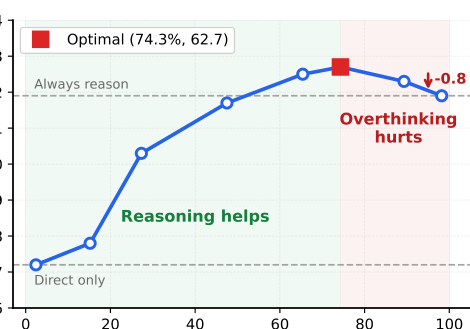
Ablations
The ablation table quantifies component contributions on MMEB‑V2 (reported overall scores):
| Variant | Score | Δ |
|---|---|---|
| MMEmb‑R1 (Full) | 65.0 | – |
| Single‑teacher rationale | 61.2 | −3.8 |
| w/o pair‑aware selection (uniform) | 62.8 | −2.2 |
| w/o counterfactual (use c_r only) | 64.1 | −0.9 |
| w/o L_reason (Direct only) | 59.2 | −5.8 |
| Always reason | 63.6 | −1.4 |
| Always direct | 60.4 | −4.6 |
| Random (50%) | 60.6 | −4.4 |
| Oracle (select best of direct/reason) | 66.2 | +1.2 |
Takeaways: (1) multi‑worker diversity and pair‑aware counterfactual selection are critical; (2) the reasoning path itself provides the largest single gain (L_reason ablation −5.8); (3) a learned adaptive policy outperforms naïve always/never or random strategies and approaches the oracle bound.
Qualitative and scaling analyses
Qualitative examples show adaptive skipping on unambiguous visual queries (avoiding overthinking) and invoking reasoning on temporally compositional video queries. Scaling experiments across Qwen2/2.5/3 families show consistent intra‑family gains and that architecture improvements can outperform raw parameter scaling (e.g., Qwen3‑VL‑2B surpasses Qwen2‑VL‑7B in some settings).

Reproducibility notes
- Joint training: vision encoder frozen; train projector + LLM for 3 epochs, effective batch size 256 across 8 GPUs, AdamW lr=5e−5, λ_CoT=λ_direct=1, max seq len 12288, bfloat16, DeepSpeed ZeRO‑3.
- Adaptive RL: GRPO with 8 samples per query, lr=1e−6, GRPO clip in [0.8,1.28], KL coeff 0.04, α=0.2, c=1e−3, encourage DIRECT for first 500 steps.
- Pair‑aware evaluator uses Qwen3‑VL‑32B‑Instruct; multi‑worker prompts and evaluator prompts are provided in the appendix; candidate threshold ε = −0.1 and softmax temperature γ used for weighting.
🔮 Conclusion
MMEmb‑R1 demonstrates that generative reasoning can be harnessed for contrastive multimodal embedding if treated as a latent variable and selected with pair‑aware counterfactual criteria. Paired with a utility‑aware RL policy that skips reasoning when it hurts or adds cost, the method improves retrieval and classification across Image, Video and VisDoc tasks while substantially reducing inference overhead compared to naïve CoT baselines.
Stated limitations include the pipeline (non end‑to‑end) design, binary decision granularity for reasoning, and residual inference cost when reasoning is invoked.
🛠️ Future Research Improvements
The paper explicitly calls out three concrete next steps: (1) end‑to‑end joint optimization that couples candidate generation, selection, and embedding learning; (2) richer action spaces for adaptive control (e.g., variable reasoning depth or brief vs detailed chains) rather than binary DIRECT/REASON; (3) algorithmic or architecture changes to reduce runtime cost of reasoning (faster rationale generation or compact intermediate representations) so reasoning can be used more broadly at low latency.
🏭 Potential Industry Use Scenarios
MMEmb‑R1 is directly applicable to retrieval systems where latency and accuracy tradeoffs matter: search and recommendation (precompute corpus embeddings; adaptively reason for queries that need disambiguation), multimodal QA over documents and videos (invoke CoT for compositional temporal or temporal‑causal queries), and retrieval‑augmented generation pipelines where selective reasoning can improve downstream generation relevance while controlling cost.
💬 Critical Analysis
Strengths
- Principled treatment of reasoning as a latent variable with pair‑aware, counterfactual scoring — this directly addresses the misalignment between per‑instance CoT and pairwise contrastive objectives.
- Practical adaptive control with GRPO that demonstrably reduces latency while improving performance; strong empirical gains across modalities, especially video.
- Thorough ablations showing each component's contribution and a near‑oracle adaptive policy performance.
Weaknesses and open questions
- Pipeline design: offline multi‑worker generation and selection add engineering complexity and precludes gradient flow from embedding objectives back into the candidate generation stage.
- Dependence on a strong evaluator J (Qwen3‑VL‑32B) for counterfactual scoring creates a potential single‑point bias and raises reproducibility barriers for groups without access to comparable evaluators.
- Binary decision space for the policy is coarse; many instances might benefit from a short rationale rather than a full chain, and the current reward penalization based on token length is heuristic.
- Although latency is reduced, reasoning still imposes extra compute when invoked; the approach benefits retrieval scenarios where corpus vectors can be precomputed, but general online uses remain constrained by runtime reasoning cost.
Reproducibility
The paper provides many critical hyperparameters (learning rates, batch sizes, GRPO settings, worker/evaluator models, thresholds ε and γ). Remaining reproducibility challenges are access to the exact high‑capacity proprietary worker and evaluator models and the engineering needed to generate and store DR at scale. The appendix includes prompts and RL tuning details that aid replication.
Overall assessment
MMEmb‑R1 offers a conceptually clean and empirically validated path to integrate generative reasoning into contrastive multimodal embedding. The pair‑aware counterfactual selection and utility‑aware adaptive policy are both novel in this context and effective in practice. The tradeoff is increased pipeline complexity and residual inference cost; addressing end‑to‑end training and finer‑grained action spaces are the most promising follow‑ups.
Source Metadata For Context Only
Published: 2026‑04‑07 — arXiv:2604.06156v1